

Группировка по отдельным словам
Алгоритм объединяет в группы фразы, имеющие пересечения по их составным частям — отдельным словам. Каждая группа состоит из фраз, имеющих в составе одно и то же слово.
Данный режим группировки удобен для оценки состава фраз при начальной кластеризации семантического ядра и при составлении списка минус-слов.
По умолчанию поиск выполняется в формонезависимом режиме, т.е. слова «купить» и «купил» будут считаться одинаковыми, и включающие их фразы будут сгруппированы вместе. Но это можно отключить в настройках перед началом анализа.
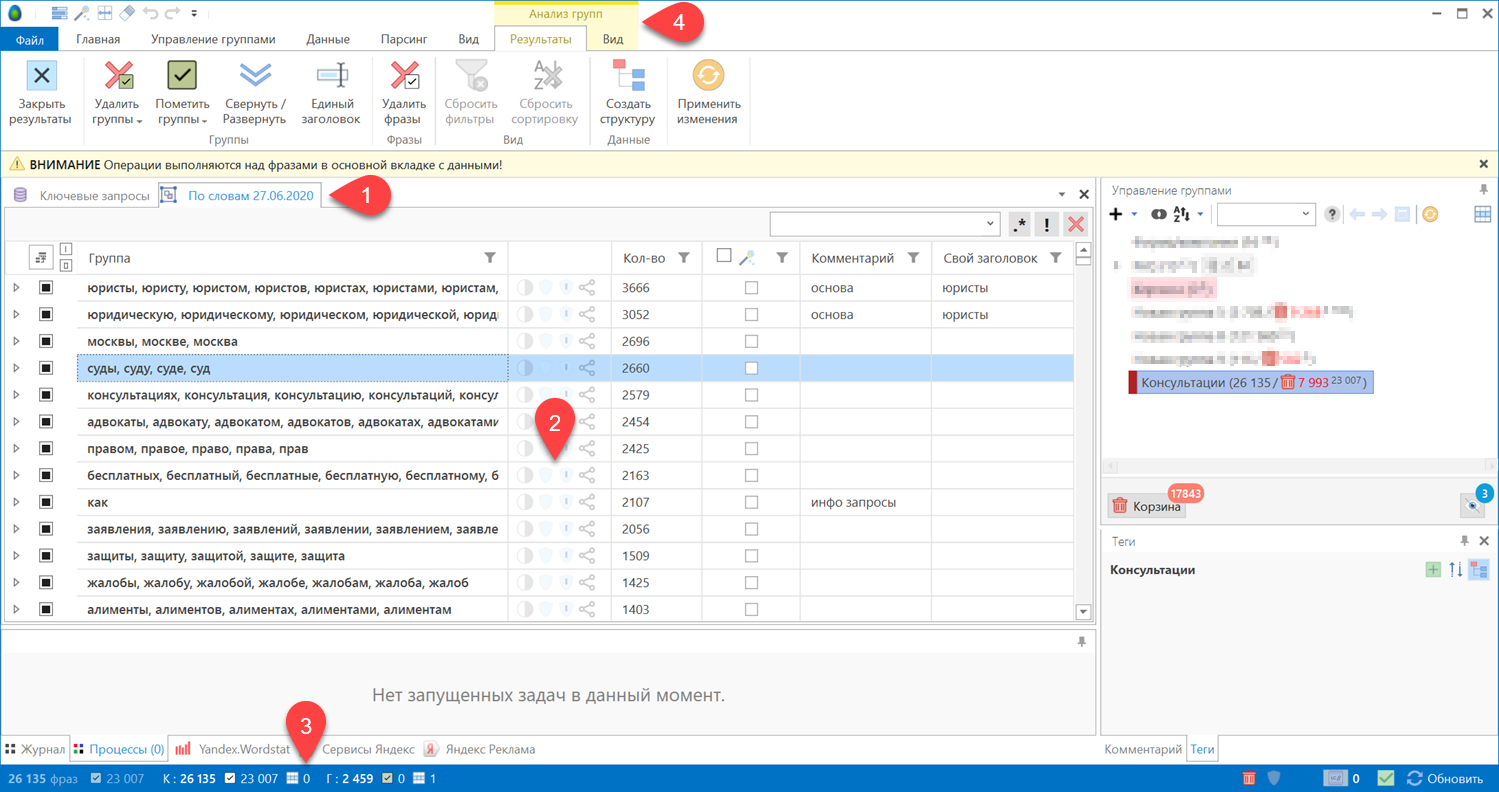
После завершения анализа в главную рабочую область добавляется вкладка с результатами группировки (1). Вы можете переименовать эту вкладку позже при сохранении изменений.
Вкладка содержит таблицу результатов группировки (2). Здесь фразы сгруппированы согласно выставленным настройкам. Каждая группа имеет дополнительные поля с размерностью группы (кол-во фраз), колонку статуса пометки, колонку произвольного комментария и колонку переопределенного заголовка группы. Также имеется колонка с функциональными кнопками.
В панели состояния добавляется блок счетчиков (3) фраз и групп в результатах группировки: общее кол-во фраз и групп, кол-во отмеченных фраз и групп, кол-во выделенных фраз и групп.
Для работы с результатами группировки в ленту инструментов добавляется группа контекстных вкладок «Анализ групп» (4).
Работа с результатами
Внутри каждой группы отображаются фразы группы вместе со статистикой из основной таблицы данных. Поддерживается пометка слов и словосочетаний, сортировка и фильтрация данных.
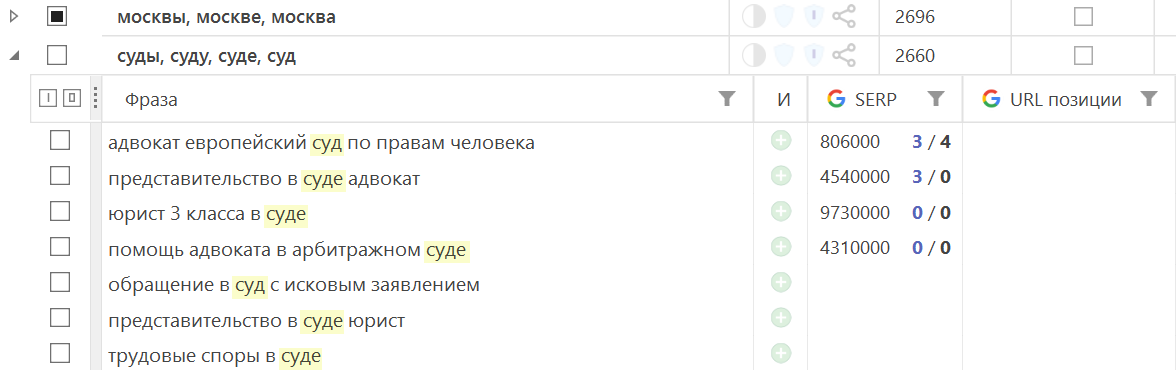
Разбивка групп
Иногда похожие по написанию слова могут иметь разные смыслы, или же задача требует разделения некоторых запросов в частном порядке. Вы можете разбить группу для несколько, воспользовавшись кнопкой справа от названия группы.
В окне разбивки выберите слова для обработки и действие: разбивку на отдельные группы для каждого из отмеченных слов или консолидацию фраз с отмеченными словами в новую общую группу
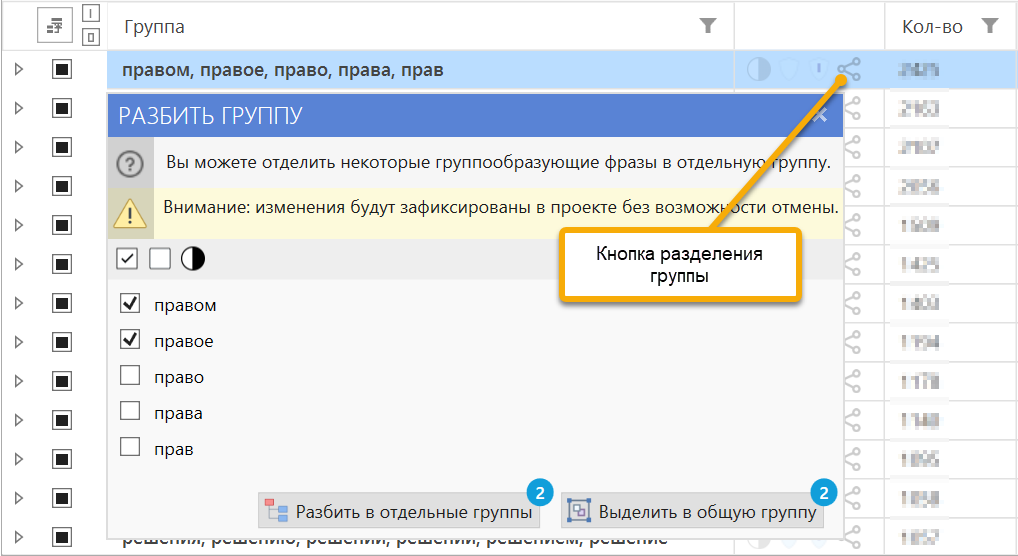
Отделение групп в новую группу
Работа с минус-словами
Слова из заголовков или самих фраз можно отправить в минус-слова через контекстное меню или кнопки справа от названия группы.
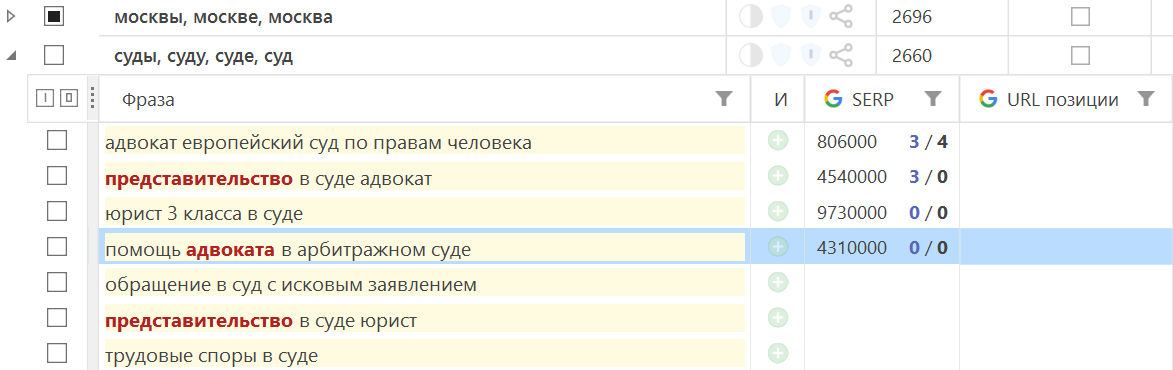
Создание структуры
Вы можете скопировать структуру, полученную в результатах группировки, в основные группы проекта.
Настройки
-
Рассматривать только отфильтрованные фразы
При использовании этой опции только фразы, удовлетворяющие текущим условиям фильтрации в группе, будут рассматриваться алгоритмом.
Опция может потребоваться при необходимости выполнить группировку некоторого подмножества фраз в большой группе.
-
Следить за статусом отметки в группах
Группа фраз в результатах группировки имеет статус отметки, вычисляемый на основе статусов отметки фраз внутри этой группы.

Вычисление состояния этого элемента интерфейса занимает время, и это может ощущаться при работе с огромными проектами.
Если опция выключена, программа не пытается автоматически обновлять это состояние.
Если вы ощущаете замедление работы интерфейса программы, можно попробовать отключить эту опцию.
-
Первичные данные
Таблица результатов содержит столбец «Сумма»для каждой группы.

В нем отображается сумма значений выбранного в параметре «Первичные данные» параметра для всех фраз внутри группы.
Если вы используете этот столбец для сортировки или фильтрации групп в результатах, укажите столбец первичных данных. В остальных случаях можно этого не делать, чтобы не выполнять лишние вычисления.
-
Использовать исключения
Опция позволяет задать список исключений (отдельных слов), которые будут полностью игнорироваться в процессе группирования фраз.
Как правило, здесь указываются предлоги, союзы, частицы и другие связующие части речи, чтобы не загрязнять результаты группировки лишними группами, однако вы можете внести и другие слова.
-
Не группировать похожие слова
По умолчанию алгоритм формирует группы из различных словоформ одного и того же слова: «юрист», «юристы», «юристам» и т.д.
Использование этой опции позволяет заставить алгоритм формировать изолированные группы для каждой словоформы в отдельности.