

Сбор фраз
Инструменты пакетного сбора фраз позволяют расширить семантическое ядро путем сбора идей запросов из различных источников.
В зависимости от конкретного модуля функционал может немного отличаться, но в общем смысле инструменты похожи.
Формирование задания
Для запуска пакетного сбора сперва нужно выбрать режим сбора: добавление в текущую активную группу или сложный сбор в режиме распределения по группам (1).
Далее необходимо ввести запросы для обработки (2) и выбрать режим добавления запросов, задать настройки сбора (3).
Запросы можно вводить вручную или загрузить из внешнего файла. При работе в режиме распределения по группам пакеты для обработки можно сформировать вручную или воспользоваться функцией автоматического распределения по группам ![]() .
.
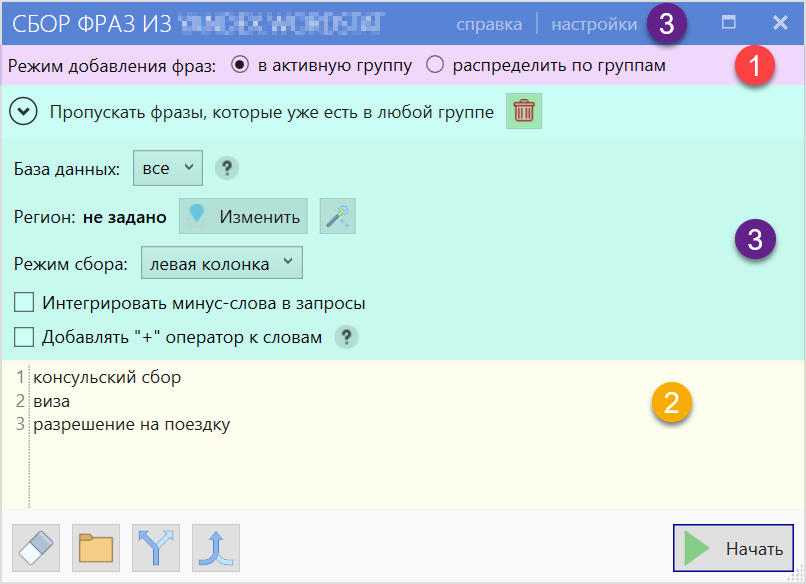
Образец окна пакетного сбора
Распределение по группам
В режиме распределения по группам вы можете указать целевые группы для добавления результатов по каждому из запросов.
В дереве групп (1) двойным кликом по заголовку или специальными кнопками на панели (3) выберите нужные группы, а затем введите запросы в панели формирования очереди (2).
Изучите подсказки к кнопкам ![]()
![]() , позволяющим автоматически наполнить выбранные целевые группы фразами из этих групп или их заголовками.
, позволяющим автоматически наполнить выбранные целевые группы фразами из этих групп или их заголовками.
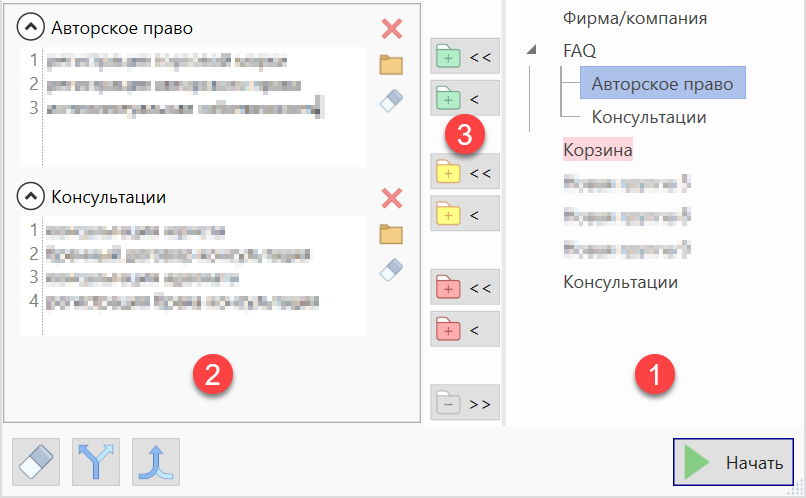
Панель распределения по группам
Автоматическое распределение
Иногда заранее известен набор фраз для обработки, но группы еще не созданы. В этом случае вы можете автоматически создать распределение по группам.
- Шаг 1. Выберите режим добавления фраз «Добавить в текущую группу».
- Шаг 2. Введите список запросов.
- Шаг 3. Нажмите кнопку
 для автоматического создания в проекте одноименных групп и распределения по группам.
для автоматического создания в проекте одноименных групп и распределения по группам.
На шаге 2 запросы можно вводить как в виде плоского списка, так и с поддержкой вложенности (сложной структуры) в режиме Группа:Ключ.
Настройки и параметры
О режиме пропуска дубликатов фраз можно прочитать здесь. Будьте внимательны при выборе режима, т.к. от этого сильно будет зависеть результат сбора фраз.
Например, если вы обрабатываете похожие или пересекающиеся по выдаче запросы, то в режиме пропуска дубликатов в других группах в проект полная выдача попадет только для одного из запросов, который успел оказаться в очереди на обработку раньше (выдача по остальным может обрезаться, т.к. дубликаты фраз согласно выбранному режиму будут пропускаться).
-
Использовать символ запятой как разделитель между фразами
Подробное описание опции совпадает с описанием в инструменте добавления фраз.
-
Использовать режим импортирования «Группа:Ключ»
Подробное описание опции совпадает с описанием в инструменте добавления фраз.
-
Принудительно добавлять исходные фразы в таблицу
Некоторые системы не гарантируют наличие исходного запроса в результатах.
Например, по запросу «макароны» может быть выдача «макароны по-флотски», «макароны с сыром» и т.д., но сам исходный запрос «макароны» в выдаче может отсутствовать.
Использование этой опции позволяет принудительно добавлять исходные запросы в результаты сбора.
Принудительно добавляемый запрос подчиняется всем правилам добавления фраз, и может быть пропущен, если таковы требования выбранных режимов и настроек. -
Глубина парсинга
При использовании ненулевой глубины парсинга программа автоматически будет подставлять собранные ранее результаты по запросу в качестве исходных запросов на следующей итерации.
Использование глубины > 0 целесообразно, если вы хотите извлечь максимальное количество результатов по исходному запросу. При этом собранные дополнительные варианты могут незначительно отличаться по теме от исходного введенного вручную запроса.
Без явной необходимости рекомендуем использовать глубину парсинга = 0.Альтернативой глубинному исследованию запросов является полуавтоматическая обработка, когда сперва вы получаете результаты при глубине = 0, затем выполняете предварительную фильтрацию данных (опционально можно удалить заведомо ненужные фразы), затем копируете оставшиеся фразы и используете их в качестве входных на следующей итерации.
В таком случае вы получаете полный контроль на прогрессом выполнения задачи, возможность без потерь приостанавливать и возобновлять сбор данных, возможность сократить время обработки за счет удаления заведомо ненужных запросов. -
Парсить страниц
Многие сервисы отображают результаты в постраничном режиме. Данный параметр отвечает за кол-во просматриваемых программой страниц.
В зависимости от задач (экспресс-анализ или полный сбор) можно устанавливать небольшие или максимальные значения параметра.
-
Обновлять статистику для существующих в таблице фраз
В процессе сбора фраз в результатах сбора может встретиться фраза, которая уже присутствует в целевой группе фраз.
Если вы хотите, чтобы программа принудительно обновила ранее записанные для такой фразы данные статистики на только что полученные свежие, то включите эту опцию.
Автоматическое назначение региона
В некоторых инструментах, поддерживающих выбор региона при сборе данных, может присутствовать функция автоматического назначения региона для одноименных с названием региона групп.
Эта функция может пригодится, если структура проекта содержит подгруппы регионов для некоторых категорий структуры. Например, это может встретиться при составлении семантического ядра интернет-магазинов.
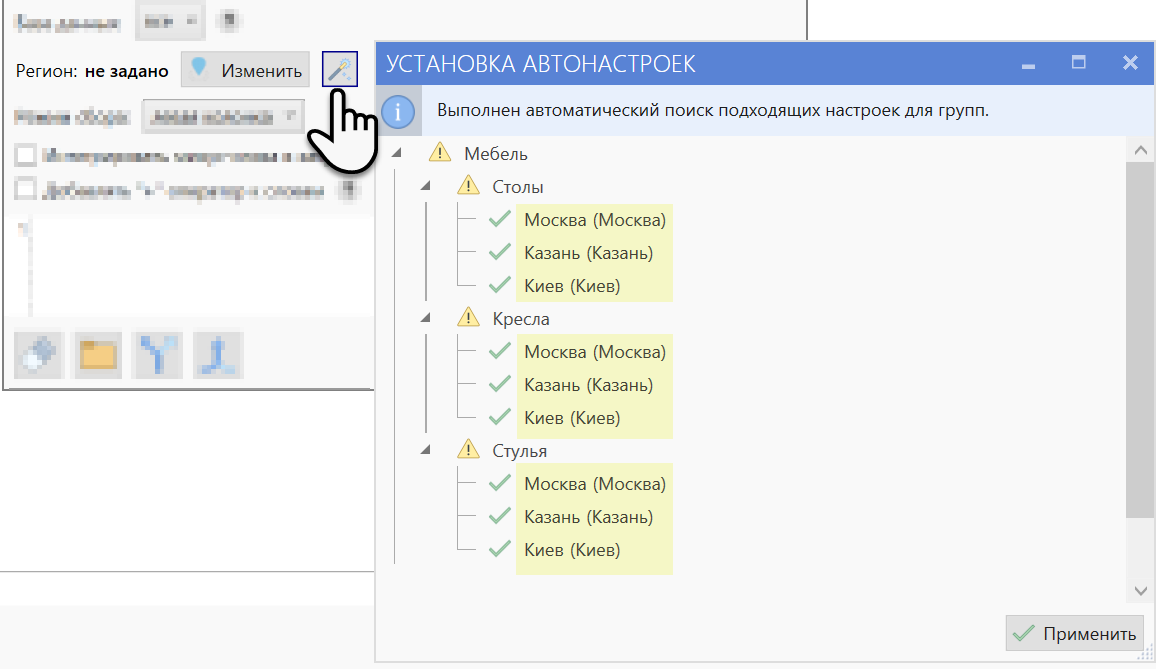
Нажмите кнопку автоматического задания регионов, и программа выполнит поиск групп в проекте, заголовки которых совпадают с поддерживаемыми названиями регионов.
Сбор статистики
Можно не только собирать новые фразы, но и получать статистику для существующих в проекте фраз без добавления новых. Причем данные можно периодически обновлять.
Узнать больше