

Группировка по поисковой выдаче
Алгоритм объединяет в группы фразы с похожей поисковой выдачей. Чем больше совпадений между результатами поисковой выдачи по запросам — тем с большей вероятностью они окажутся в одной группе.
Данный режим группировки удобен для автоматической кластеризации семантического ядра.
Группировка по поисковой выдаче v.3 использует другой алгоритм объединения фраз по объединению и пересечению признаков (также известный как SOFT и HARD). Она способна быстро и качественно разгруппировать большие объемы фраз.
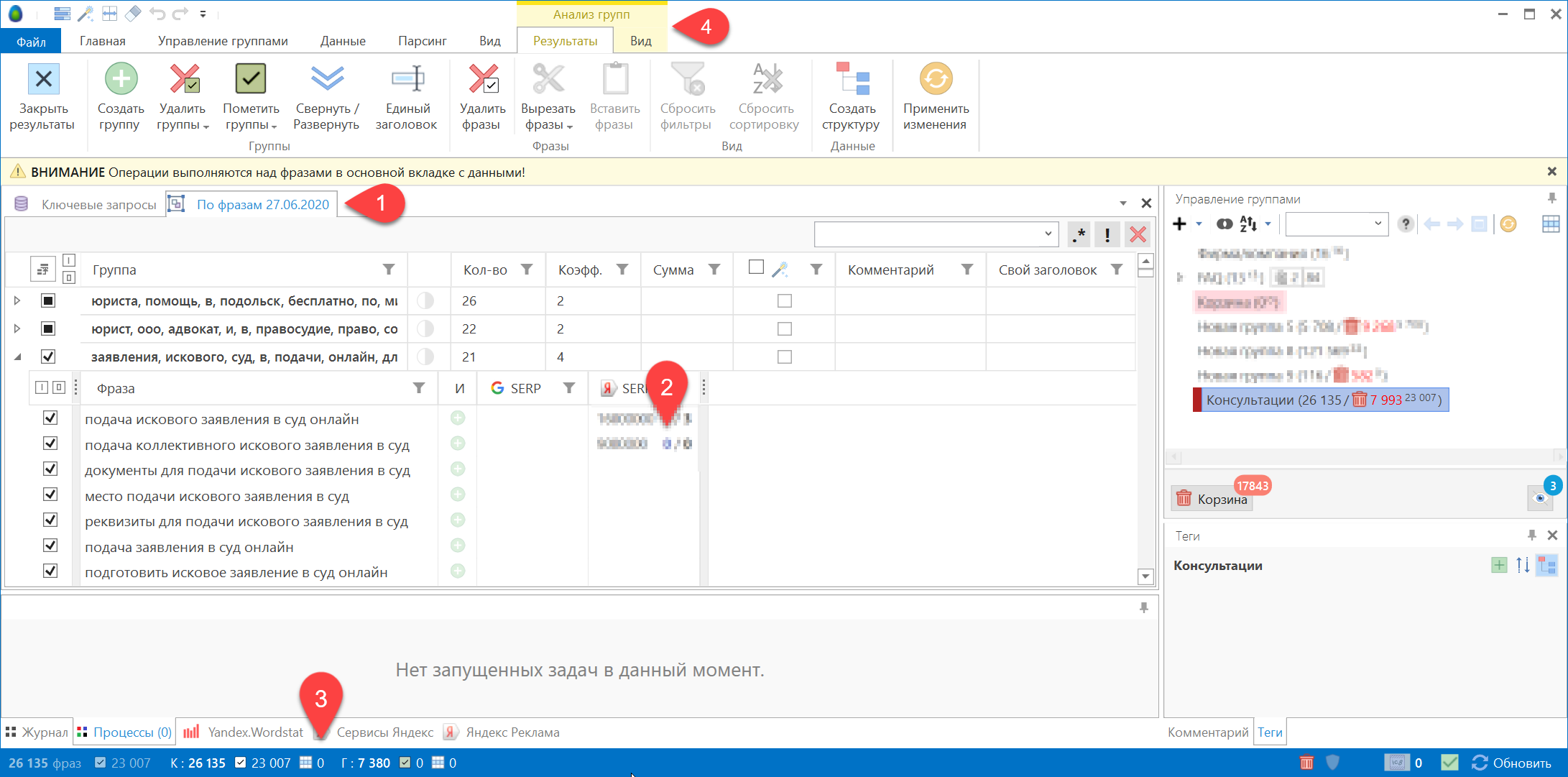
После завершения анализа в главную рабочую область добавляется вкладка с результатами группировки (1). Вы можете переименовать эту вкладку позже при сохранении изменений.
Вкладка содержит таблицу результатов группировки (2). Здесь фразы сгруппированы согласно выставленным настройкам. Каждая группа имеет дополнительные поля с размерностью группы (кол-во фраз), колонку статуса пометки, колонку произвольного комментария и колонку переопределенного заголовка группы. Также имеется колонка с функциональными кнопками.
В панели состояния добавляется блок счетчиков (3) фраз и групп в результатах группировки: общее кол-во фраз и групп, кол-во отмеченных фраз и групп, кол-во выделенных фраз и групп.
Для работы с результатами группировки в ленту инструментов добавляется группа контекстных вкладок «Анализ групп» (4).
Работа с результатами
Внутри каждой группы отображаются фразы вместе со статистикой из основной таблицы данных. Поддерживается сортировка и фильтрация данных.
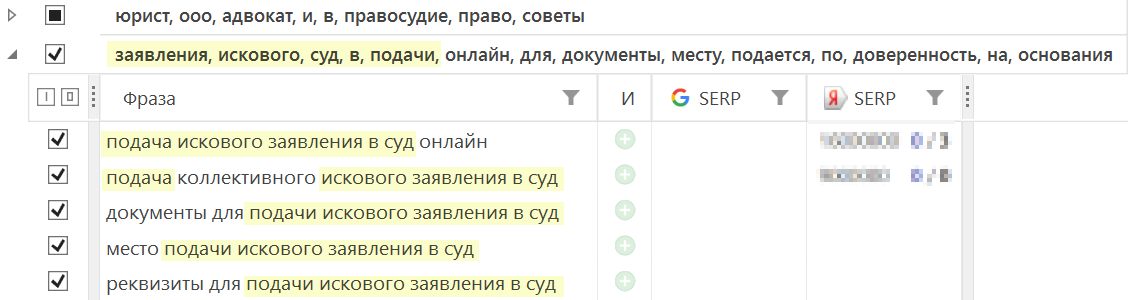
Колонка «Коэфф.» (коэффициент) отражает степень связи между фразами в группе: чем больше значение коэффициента — тем более похожи фразы внутри группы.
Редактирование группировки
Группировка по составу фраз может скорректирована вручную: группы могут быть созданы или удалены, фразы могут быть перемещены между группами.
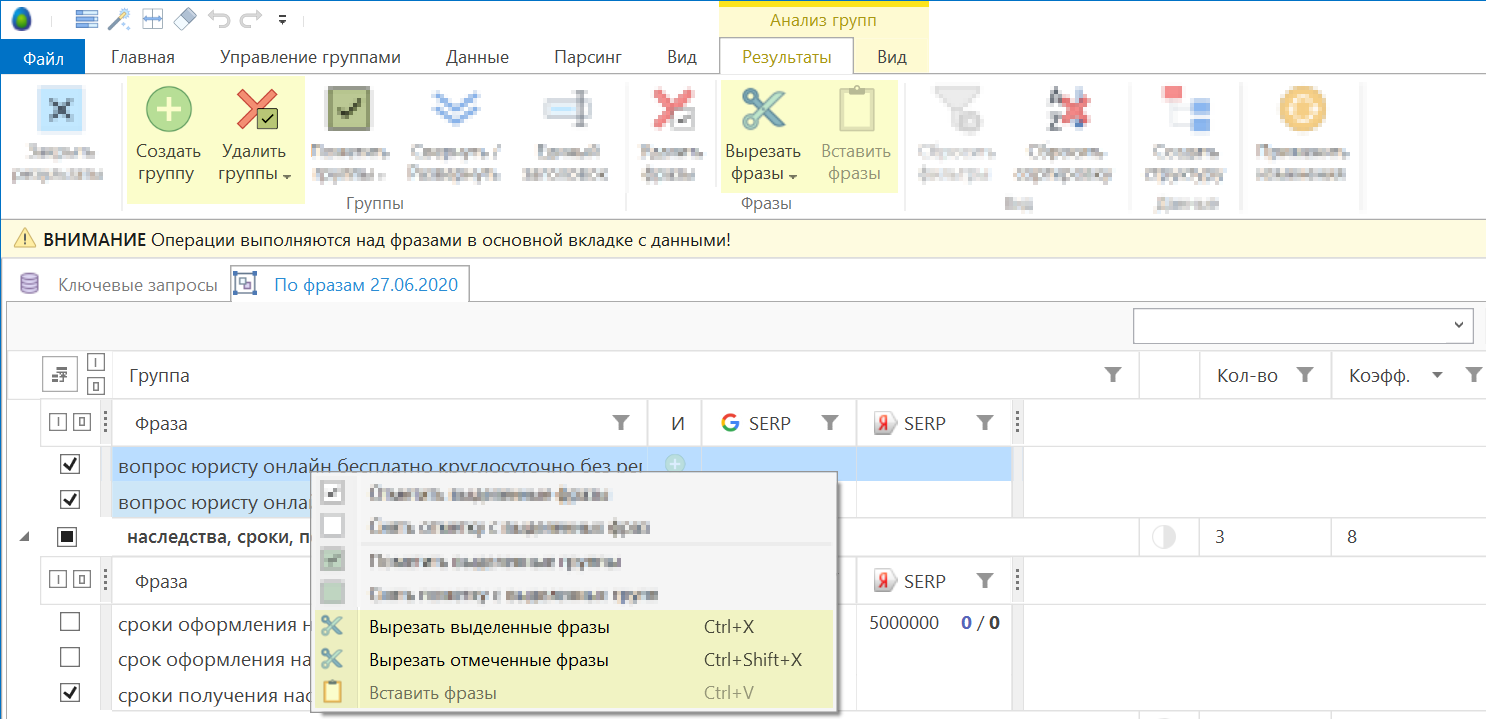
Создание структуры
Вы можете скопировать структуру, полученную в результатах группировки, в основные группы проекта.
Настройки
-
Рассматривать только отфильтрованные фразы
При использовании этой опции только фразы, удовлетворяющие текущим условиям фильтрации в группе, будут рассматриваться алгоритмом.
Опция может потребоваться при необходимости выполнить группировку некоторого подмножества фраз в большой группе.
-
Следить за статусом отметки в группах
Группа фраз в результатах группировки имеет статус отметки, вычисляемый на основе статусов отметки фраз внутри этой группы.

Вычисление состояния этого элемента интерфейса занимает время, и это может ощущаться при работе с огромными проектами.
Если опция выключена, программа не пытается автоматически обновлять это состояние.
Если вы ощущаете замедление работы интерфейса программы, можно попробовать отключить эту опцию.
-
Колонка суммы
Таблица результатов содержит столбец «Сумма»для каждой группы.

В нем отображается сумма значений выбранного в параметре «Колонка суммы» параметра для всех фраз внутри группы.
Если вы используете этот столбец для сортировки или фильтрации групп в результатах, укажите столбец суммы. В остальных случаях можно этого не делать, чтобы не выполнять лишние вычисления.
-
Колонка средних
Таблица результатов содержит столбец «Ср.зн.» (среднее значение) для каждой группы.
В нем отображается среднее арифметическое значений выбранного в параметре «Колонка средних» параметра для всех фраз внутри группы.
Если вы используете этот столбец для сортировки или фильтрации групп в результатах, укажите столбец средних. В остальных случаях можно этого не делать, чтобы не выполнять лишние вычисления.
-
Сила группировки
Сила группировки определяет минимальный порог совпадений между любыми двумя фразами, чтобы алгоритм начал рассматривать их как похожие фразы для включения в одну группу.
Если требуется получить более широкие группы, то уменьшите силу группировки, а если нужны группы сильно похожих друг на друга запросов — увеличьте силу.
-
Мин. размер группы
Параметр минимального размера группы определяет, сколько фраз должно минимально содержаться в группе для ее создания.
Если алгоритм не смог найти заданное кол-во подходящих для включения в единую групп фраз, то он попытается распределить эти фразы по другим ранее сформированным группам допустимого размера.
Если указать слишком большой минимальный размер группы, то много запросов могут не найти себе подходящей группы и останутся не сгруппированы. В этом случае можно попробовать уменьшить мин. размер группы.
-
Учитывать сперва сильные связи
В процессе группировки алгоритм сравнивает похожие друг на друга фразы и подсчитывает кол-во совпадений. Найденные похожие фразы могут иметь различное кол-во совпадений с рассматриваемой фразой.
Если опция включена, то на одном шаге алгоритм сгруппирует только наиболее тесно связанные фразы, а другие менее похожие отложит на потом для следующей итерации.
Использование данное опции может немного увеличить время анализа, а также может привести к формированию более точно подобранных и тесных групп.
-
Усиливать связи в группах
В процессе группировки алгоритм сравнивает похожие друг на друга фразы, подсчитывает кол-во совпадений и группирует фразы.
Если опция включена, то после завершения группировки алгоритм проверяет наличие более тесных связей для сгруппированных ранее фраз и перемещает их между группами при наличии возможности.
Например, если выясняется, что ранее сгруппированная фраза 1, допустим, по 5 совпадениям имеет похожую и тоже сгруппированную фразу 2 по 7 совпадениям (ее группа создавалась позже), то фраза 1 может быть перемещена в эту более подходящую и тесную группу.
Использование данное опции может увеличить время анализа, а также может привести к формированию более точно подобранных и тесных групп.
-
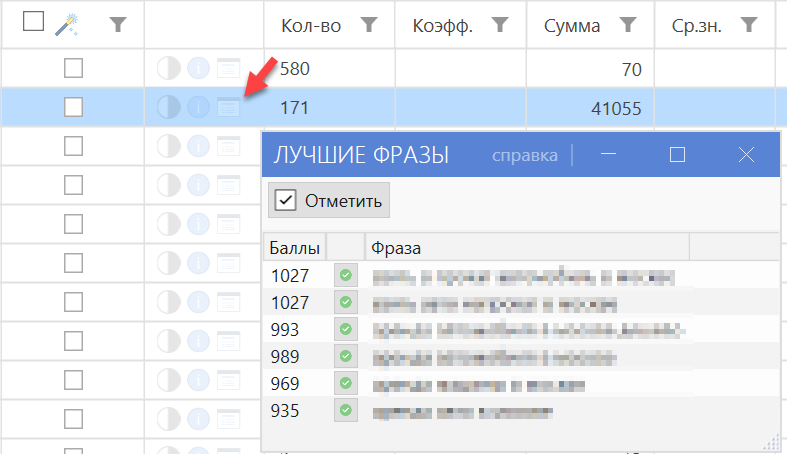
Вычислять лучшие фразы в группе
Если опция включена, то после завершения группировки алгоритм находит лучшие фразы в группе — фразы, которые больше всех похожи на все остальные фразы группы.
Лучшей фразой считается такая фраза, которая имеет наибольшее кол-во совпадений по критерию выбранного алгоритма группировки с остальными фразами рассматриваемой группы.
Просмотр списка лучших фраз возможен в таблице результатов группировки.
-
Записывать лучшую фразу в свой заголовок
Если опция включена, то после завершения группировки алгоритм находит лучшие фразы в группе, а затем записывает одну из них в поле «Свой заголовок» для каждой из найденных групп.
Лучшей фразой считается такая фраза, которая имеет наибольшее кол-во совпадений по критерию выбранного алгоритма группировки с остальными фразами рассматриваемой группы.
В дальнейшем вы можете лучше понимать суть найденных групп по найденным маркерным запросам. Также поле «Свой заголовок» может использоваться при создании структуры групп в качестве заголовка групп.
Просмотр списка лучших фраз возможен в таблице результатов группировки.
-
Показывать статистику групп
Если опция включена, то после завершения группировки под таблицей результатов появится панель статистики выделенной группы.
В настоящий момент там отображается метрика тренда по выбранной колонке.
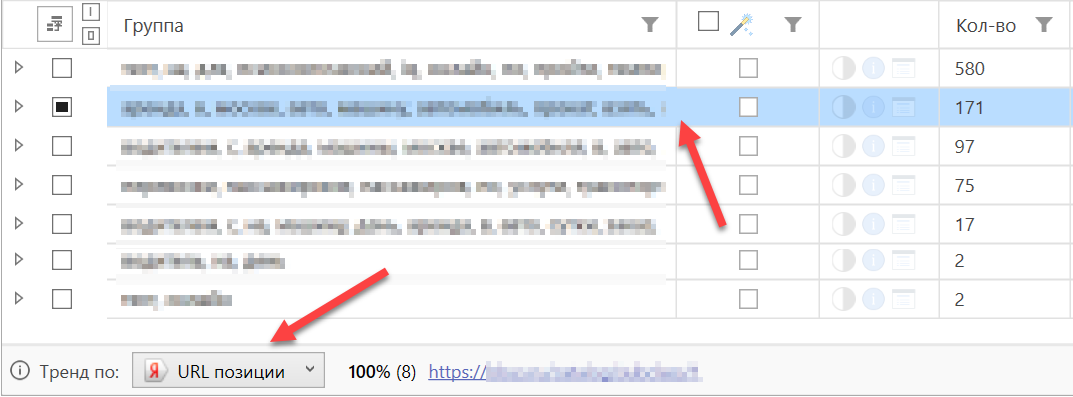
Выберите колонку для исследования и выделите любую группу в таблице результатов. Программа подсчитает долю и кол-во каждого из уникальных значений в выбранной колонке для фраз группы.
Например, можно выяснить, какие страницы находятся в ТОП по снятым позициям. Или же распределение пользовательских комментариев.
-
Несгруппированные фразы
Некоторые фразы могут остаться несгруппированными либо из-за их непохожести на остальные запросы, либо из-за высоких значений силы группировки, либо если алгоритм не нашел для них подходящей группы.
Эта опция определяет, что произойдет с такими фразами: они могут быть скрыты из результатов группировки, либо объединены в отдельную группу несгруппированных запросов.
-
Ограничение TOP
В зависимости от выбранного значения алгоритм будет искать совпадения между результатами в поисковой выдаче только в пределах первых N адресов (ограничение по TOP).
-
Источник
Алгоритм будет исследовать результаты поисковой выдачи только для выбранных поисковых систем.
-
Разбивать группы по силе
По умолчанию если некоторая фраза 1 имеет N совпадений с другой фразой 2, имеющей более сильную связь из M совпадений с какой-то другой фразой 3 (N < M), то фраза 1 может быть присоединена к группе, где находится фраза 3. Другими словами, сильная связь может притягивать к себе слабые, если для них нет более подходящих кандидатов.
Если опция включена, то фраза 1 из рассмотренного выше примера не будет притягиваться к сильной связи степени M, а образует новую группу.
-
Список исключений
При группировке по поисковой выдаче вы можете захотеть на учитывать совпадения между фразами по некоторым популярным сайтам. Например, можно не учитывать аукционы, сервисы ПС и пр.
Здесь вы можете ввести домены в формате site.ru или *.site.ru (* - любой поддомен).
Обратите внимание, что вписав site.ru, вы не исключаете shop.site.ru (поддомены этого сайта), а вписав *.site.ru вы не исключаете site.ru (основной сайт без поддомена).