

Группировка по конкурентам
Алгоритм выполняет поиск наиболее сильных конкурентов по заданному набору фраз и группирует фразы по принадлежности к найденным конкурентам.

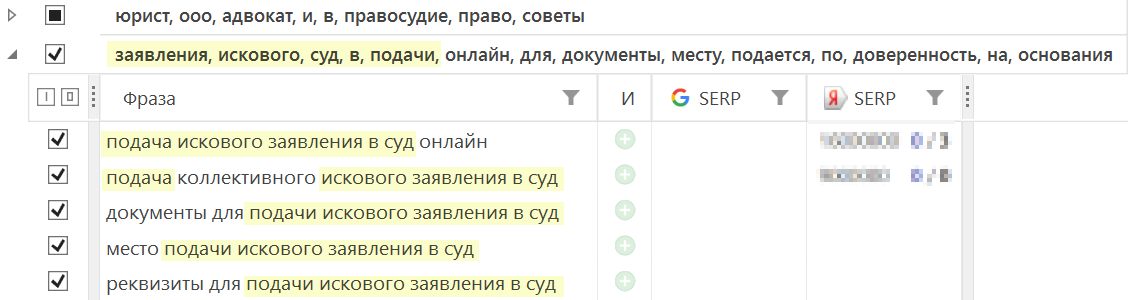
После завершения анализа в главную рабочую область добавляется вкладка с результатами группировки (1). Вы можете переименовать эту вкладку позже при сохранении изменений.
Вкладка содержит таблицу результатов группировки (2). Здесь фразы сгруппированы согласно выставленным настройкам. Каждая группа имеет дополнительные поля с размерностью группы (кол-во фраз), колонку статуса пометки, колонку произвольного комментария и колонку переопределенного заголовка группы. Также имеется колонка с функциональными кнопками.
В панели состояния добавляется блок счетчиков (3) фраз и групп в результатах группировки: общее кол-во фраз и групп, кол-во отмеченных фраз и групп, кол-во выделенных фраз и групп.
Для работы с результатами группировки в ленту инструментов добавляется группа контекстных вкладок «Анализ групп» (4).
Работа с результатами
Внутри каждой группы отображаются фразы вместе со статистикой из основной таблицы данных. Поддерживается сортировка и фильтрация данных.
Создание структуры
Вы можете скопировать структуру, полученную в результатах группировки, в основные группы проекта.
Настройки
-
Рассматривать только отфильтрованные фразы
При использовании этой опции только фразы, удовлетворяющие текущим условиям фильтрации в группе, будут рассматриваться алгоритмом.
Опция может потребоваться при необходимости выполнить группировку некоторого подмножества фраз в большой группе.
-
Следить за статусом отметки в группах
Группа фраз в результатах группировки имеет статус отметки, вычисляемый на основе статусов отметки фраз внутри этой группы.

Вычисление состояния этого элемента интерфейса занимает время, и это может ощущаться при работе с огромными проектами.
Если опция выключена, программа не пытается автоматически обновлять это состояние.
Если вы ощущаете замедление работы интерфейса программы, можно попробовать отключить эту опцию.
-
Первичные данные
Таблица результатов содержит столбец «Сумма»для каждой группы.

В нем отображается сумма значений выбранного в параметре «Первичные данные»параметра для всех фраз внутри группы.
Если вы используете этот столбец для сортировки или фильтрации групп в результатах, укажите столбец первичных данных. В остальных случаях можно этого не делать, чтобы не выполнять лишние вычисления.
-
Минимальный процент охвата фраз для конкурента
Этот параметр задает нижнюю границу видимости сайта в процентах относительно общего исследуемого кол-ва фраз для рассмотрения этого сайта в качестве конкурента.
Например, если установить высокую мин. границу 30%, мелкие сайты практически не будут иметь возможности попасть в список конкурентов.
-
Режим поиска
Алгоритм может рассматривать результаты в поисковой выдаче по запросам на уровне доменов или полных адресов страниц (с параметрами и без).
Режим поиска напрямую влияет на результаты группировки и поиска.
При использовании поиска на уровне доменов, страницы site.com/products/ и site.com/about будут считаться одинаковыми (домен site.com).
-
Ограничение TOP
В зависимости от выбранного значения алгоритм будет искать совпадения между результатами в поисковой выдаче только в пределах первых N адресов (ограничение по TOP).
-
Источник
Алгоритм будет исследовать результаты поисковой выдачи только для выбранных поисковых систем.
-
Список исключений
Вы можете исключить из результатов некоторые ресурсы. Вводите домены каждый с новой строки.
Например, можно убрать из результатов информационные сайты или справочники.
-
Правила рассмотрения фраз
При анализе могут рассматриваться только фразы, имеющие в поисковой выдаче сайты из указанного списка. Каждый сайт вводите с новой строки.
При использовании этого режима общее кол-во фраз для расчета процента видимости конкурента корректируется на кол-во фраз, выдача которых содержит указанные ресурсы.