

Группировка по составу фраз
Алгоритм объединяет в группы похожие фразы. Чем больше фразы похожи друг на друга — тем с большей вероятностью они окажутся в одной группе.
Данный режим группировки удобен для автоматической кластеризации семантического ядра.
Группировка по составу фраз v.2 использует другой итеративный алгоритм объединения фраз на основе близости центров кластеров. В некоторых случаях результаты могут оказаться более точными. Анализ занимает больше времени и ресурсов, поэтому является альтернативным, а не основным.
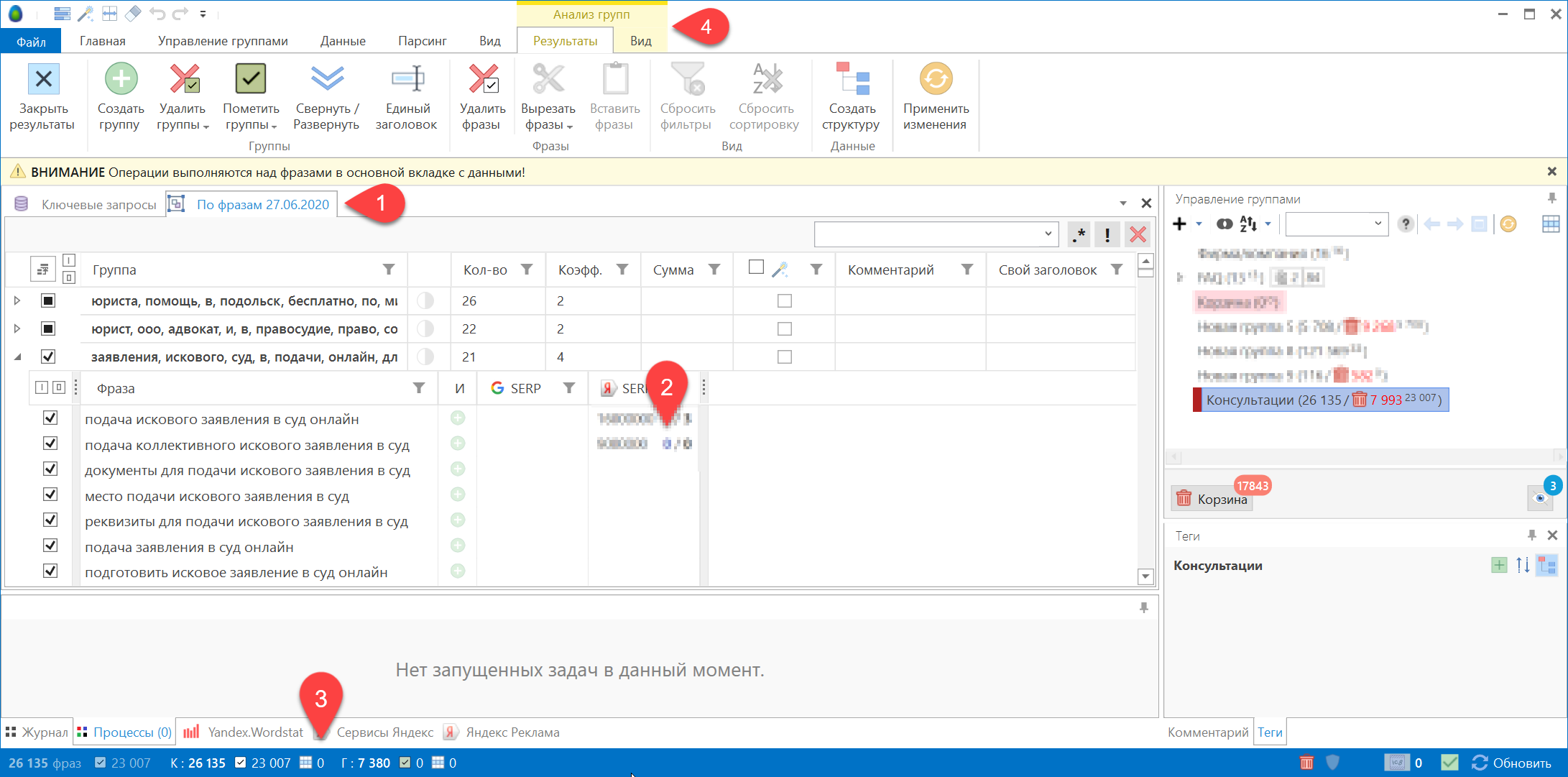
После завершения анализа в главную рабочую область добавляется вкладка с результатами группировки (1). Вы можете переименовать эту вкладку позже при сохранении изменений.
Вкладка содержит таблицу результатов группировки (2). Здесь фразы сгруппированы согласно выставленным настройкам. Каждая группа имеет дополнительные поля с размерностью группы (кол-во фраз), колонку статуса пометки, колонку произвольного комментария и колонку переопределенного заголовка группы. Также имеется колонка с функциональными кнопками.
В панели состояния добавляется блок счетчиков (3) фраз и групп в результатах группировки: общее кол-во фраз и групп, кол-во отмеченных фраз и групп, кол-во выделенных фраз и групп.
Для работы с результатами группировки в ленту инструментов добавляется группа контекстных вкладок «Анализ групп» (4).
Работа с результатами
Внутри каждой группы отображаются фразы группы вместе со статистикой из основной таблицы данных. Поддерживается сортировка и фильтрация данных.
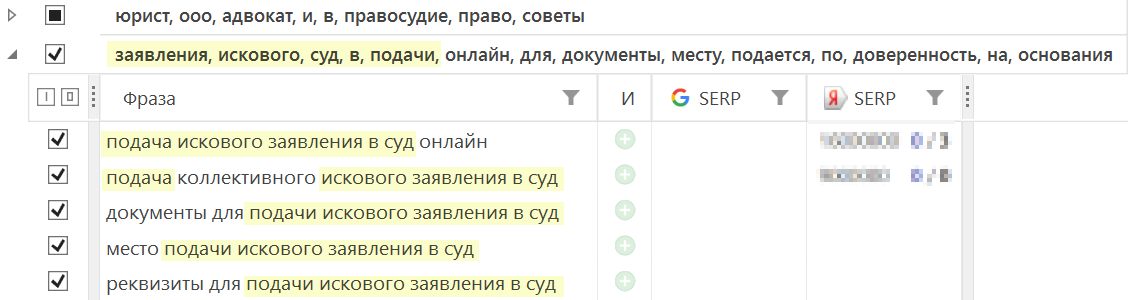
Колонка «Коэфф.» (коэффициент) отражает степень связи между фразами в группе: чем больше значение коэффициента — тем более похожи фразы внутри группы.
Редактирование группировки
Группировка по составу фраз может скорректирована вручную: группы могут быть созданы или удалены, фразы могут быть перемещены между группами.
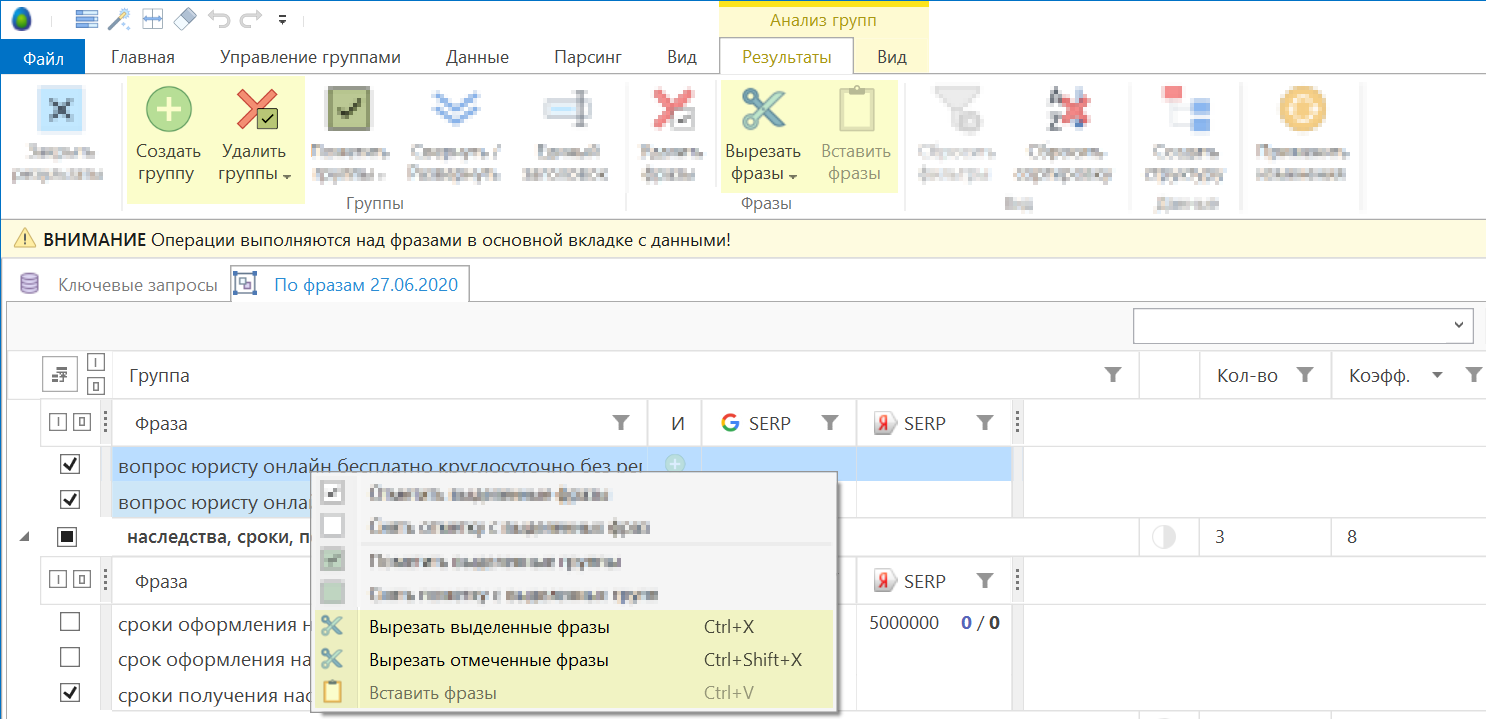
Создание структуры
Вы можете скопировать структуру, полученную в результатах группировки, в основные группы проекта.
Настройки
-
Рассматривать только отфильтрованные фразы
При использовании этой опции только фразы, удовлетворяющие текущим условиям фильтрации в группе, будут рассматриваться алгоритмом.
Опция может потребоваться при необходимости выполнить группировку некоторого подмножества фраз в большой группе.
-
Следить за статусом отметки в группах
Группа фраз в результатах группировки имеет статус отметки, вычисляемый на основе статусов отметки фраз внутри этой группы.

Вычисление состояния этого элемента интерфейса занимает время, и это может ощущаться при работе с огромными проектами.
Если опция выключена, программа не пытается автоматически обновлять это состояние.
Если вы ощущаете замедление работы интерфейса программы, можно попробовать отключить эту опцию.
-
Первичные данные
Таблица результатов содержит столбец «Сумма»для каждой группы.

В нем отображается сумма значений выбранного в параметре «Первичные данные»параметра для всех фраз внутри группы.
Если вы используете этот столбец для сортировки или фильтрации групп в результатах, укажите столбец первичных данных. В остальных случаях можно этого не делать, чтобы не выполнять лишние вычисления.
-
Сила группировки
Сила группировки определяет минимальный порог совпадений между любыми двумя фразами, чтобы алгоритм начал рассматривать их как похожие фразы для включения в одну группу.
Если требуется получить более широкие группы, то уменьшите силу группировки, а если нужны группы сильно похожих друг на друга запросов — увеличьте силу.
-
Несгруппированные фразы
Некоторые фразы могут остаться несгруппированными либо из-за их непохожести на остальные запросы, либо из-за высоких значений силы группировки, либо если алгоритм не нашел для них подходящей группы.
Эта опция определяет, что произойдет с такими фразами: они могут быть скрыты из результатов группировки, либо объединены в отдельную группу несгруппированных запросов.
-
Пропускать малозначимые слова
В процессе процессе подсчета кол-ва совпадений между фразами можно исключить из рассмотрения предлоги, союзы, частицы или другие не имеющие отношение к тематике проекта слова.
Использование списка малозначимых слов позволяет повысить качество работы алгоритма.
-
Использовать синонимы
В процессе процессе подсчета кол-ва совпадений между фразами можно учитывать эквивалентность разных по написанию, но одинаковых по смыслу слов или словосочетаний — синонимов.
Под синонимами в программе понимаются не настоящий синонимы русского языка, а эквивалентные слова и словосочетания, заданные пользователем в настройках.Использование синонимов позволяет повысить качество работы алгоритма.
Список синонимов определяется в «Настройках - Анализ слов - Синонимы».
Например, «МРТ» и «магнитно резонансная томография» (расшифровка аббревиатуры) или «кислый» и «горький» (вкус) могут считаться совпадениями.
Этот режим может замедлять скорость анализа на огромных проектах. -
Игнорировать числа
В процессе процессе подсчета кол-ва совпадений между фразами алгоритм может пропускать числа.
Использование синонимов позволяет повысить качество работы алгоритма, если числа в тексте фраз не имеют значения в контексте вашего проекта.
-
Разбивать группы по силе
По умолчанию если некоторая фраза 1 имеет N совпадений с другой фразой 2, имеющей более сильную связь из M совпадений с какой-то другой фразой 3 (N < M), то фраза 1 может быть присоединена к группе, где находится фраза 3. Другими словами, сильная связь может притягивать к себе слабые, если для них нет более подходящих кандидатов.
Если опция включена, то фраза 1 из рассмотренного выше примера не будет притягиваться к сильной связи степени M, а образует новую группу.
-
Режим сканирования
После подсчета кол-ва совпадений между фразами начинается процесс группировки.
В зависимости от выбранного режима сканирования алгоритм может начать формировать группы либо от фраз с сильными связями (от точных к широким; с большим кол-вом совпадений) и присоединять к ним более слабые, либо наоборот: начать с фраз слабой связи (от широких к точным; как правильно, короткие словосочетания), а потом формировать группы из фраз с сильными связями.
При группировке от широких к точным может получиться больше групп из коротких словосочетаний, а группы с длинными фразами будут более точными с меньшим кол-вом примесей.